| Druid连接池核心原理 | 您所在的位置:网站首页 › druid 数据库 › Druid连接池核心原理 |
Druid连接池核心原理
|
一、什么是Druid连接池? Druid连接池是阿里巴巴开源的数据库连接池项目。Druid连接池为监控而生,内置强大的监控功能,监控特性不影响性能。功能强大,能防SQL注入,内置Loging能诊断Hack应用行为。 竞品对比 说明: ExceptionSorter:官方的说明这是Druid连接池稳定性的保证,用于处理重大的不可恢复的异常,它是一个接口,不同的数据库有不同的实现类,mysql的处理类是 MySqlExceptionSorter,它的isExceptionFatal(SQLException e)方法中识别重大异常,至于如何保证Druid稳定性的,后面会有介绍; Filter:这是Druid中的又一大特色,提供了强大的扩展功能,如连接池监控(连接池配置信息、SQL执行、并发、慢查询、执行时间区间分布等,由StatFilter实现)、防止SQL注入(WallFilter)、连接池信息日志输出(LogFilter)等,Druid内置的实现如下: 二、Druid工作原理 本文是基于Druid 1.1.22版本,主要对连接池的初始化以及获取连接的工作流程介绍,这也是Druid的核心,至于其它功能,如监控、sql处理、事务等这里不做详细说明,有兴趣的同学可以自行了解。 1、连接池初始化 1.1 自动初始化 Druid初始化方法位于com.alibaba.druid.pool.DruidDataSource#init,这个方法就是初始化的核心,我们的项目启动之后是如何自动进行初始化的? 对于Springboot项目,Druid 的maven依赖如下: 1.2 初始化流程 Druid初始化大体分为以下几个部分: 1.2.1 初始化filters filters的来源主要有两个:一是通过系统参数配置:-Ddruid.filters=xxx,是个列表;二是通过SPI机制加载;主要是提供给用户扩展使用的,在获取连接的时候会通过责任链模式进行调用; 1.2.2 参数校验 主要是校验参数配置的合法性,如必须 maxActive>0、maxActive >= minIdle、maxEvictableIdleTimeMillis >= minEvictableIdleTimeMillis等等; 1.2.3 初始化ExceptionSorter和validConnectionChecker ExceptionSorter 上面说过ExceptionSorter是Druid稳定性的保证,那么它是如何保证的呢?ExceptionSorter 的作用是:在数据库服务器重启、网络抖动、连接被服务器关闭等异常情况下,连接发生了不可恢复异常,将连接从连接池中移除,保证连接池在异常发生时情况下正常工作。ExceptionSorter是连接池稳定的关键特性,没有ExceptionSorter 的连接池,不能认为是有稳定性保障的连接池。 对于mysql数据库,实现类是MySqlExceptionSorter,该类中的isExceptionFatal方法主要是筛选出特定的异常,如CommunicationsException、以及指定的errorCode等,并最终通过com.alibaba.druid.pool.DruidPooledConnection#handleException(java.lang.Throwable, java.lang.String)方法(该方法很多地方都会调用到,比如sql执行的时候、事务提交的时候、异常回滚的时候等)将DruidAbstractDataSource类中的onFatalError属性设置成true,在进行连接池维护的时候最终会通过onFatalError属性判断是否发生了不可逆的重大异常(如数据库挂了、网络中断异常等),并将连接剔除,保证连接池的稳定; ValidConnectionChecker ValidConnectionChecker是个接口,Druid初始化的时候会根据数据库的驱动类来判断数据库的类型,并为每种数据库分别生成对应的ValidConnectionChecker,如mysq数据库的实现是MySqlValidConnectionChecker。这个类很重要,用来检测连接池中连接的可用性,如果检测连接不可用,则close掉;可用的话就继续放回连接池中。具体检测的逻辑放到后面DestroyConnectionThread线程里说,因为需要配合一起才更好理解; 1.2.4 初始化连接池 DruidConnectionHolder类型的数组,有3个池子(容量都是maxActive): connections:存放正常连接,我们常说的连接池就是指这个数组 evictConnections:存放需要抛弃的连接; keepAliveConnections:存放需要进行活性检测的连接 并生成initialSize个连接存放到connections中; 1.2.5 开启3个守护线程: createAndLogThread(); createAndStartCreatorThread(); createAndStartDestroyThread(); 1.2.5.1 LogStatsThread线程 线程名:Druid-ConnectionPool-Log-当前对象hashCode,打印线程池当前配置信息,每timeBetweenLogStatsMillis执行一次,如果没有配置则该线程不执行,逻辑比较简单,主要就是封装当前线程池的信息,然后打印log,就不详细说了。 1.2.5.2 CreateConnectionThread线程 线程名:Druid-ConnectionPool-Create-当前对象hashCode,项目启动后,该线程大部分情况下都处于WAITING状态,可以用jstack命令查看。 这个线程用于创建连接并put进连接池中,它的工作流程如图: 1.2.5.3 DestroyConnectionThread线程 线程名:Druid-ConnectionPool-Destroy-当前对象hashCode,这个线程中涉及到3个池子: connections:所有连接的连接池; keepAliveConnections:存放需要进行可用性检测的连接的池子; evictConnections:存放需要抛弃的连接的池子 这个线程就是围绕着三个池子进行工作,将connections连接池中的连接经过各种条件判断进行分类,最终分成上述三个池子,最后分别对keepAliveConnections和evictConnections遍历处理,该丢弃的丢弃,该检测的检测,检测可用继续放回connections中,检测不可用丢弃。如果经过连接的丢弃之后发现连接池中的连接不够用了(池中连接的数量小于minIdle个,则唤醒CreateConnectionThread线程补充连接,注意这个功能只有当keepAlive=true时才会有) 在1.2.3中说到的ValidConnectionChecker类的作用时,用来检测连接池中连接是否可用的,具体检测的逻辑就在DestroyConnectionThread线程中,上面说到keepAliveConnections这个池子,如果最终keepAliveConnections中存在需要进行检测的连接的话,就开始通过ValidConnectionChecker类进行检测了。源码位于com.alibaba.druid.pool.DruidAbstractDataSource#validateConnection方法,详细流程如图: 2、获取连接 (2)如果自定义了Filter(Druid内置也实现了几个Filter),先执行Filter责任链 这里针对项目中遇到的问题做个总结: 问题1:数据库挂了之后,连接池中的连接变成了CLOSE_WAIT状态,会不会影响数据库操作?如果影响,需要等多久才能正常? (1)连接池中有连接(minIdle个,CLOSE_WAIT状态),极端情况下线程需要等待1分钟(timeBetweenEvictionRunsMillis),因为在第1次请求的进行连接检测的时候,就会唤醒CreateConnectionThread线程,这时候会生成一个正常连接,下次循环的时候就会get到这个正常连接使用;所以第1次请求会报错,后面再请求就正常了; (2)连接池中没有连接,如果数据库挂的时候池中没有连接,那么获取连接的时候就会等待超时:连接池的配置maxWait是指Druid在等待获取连接时的超时时间,如果没有获取到,就会默认重试一次(重试次数notFullTimeoutRetryCount指定,默认0),所以Druid获取连接等待的超时时间是maxWait2=30002=6000ms; 另外,在获取连接的同时,会唤醒CreateConnectionThread线程进行创建连接(这个过程是异步的),创建连接的时候可能也有超时时间,这个超时时间由jdbc参数connectTimeout(默认0,永不超时)指定,我们没有配置,但是配置了socketTimeout=9000(这个不是建立连接的超时时间,是socket read/write的超时时间),如果jdbc没有设置connectTimeout,就会以操作系统默认的,linux系统建立TCP连接默认超时时间127s。 问题2:查询数据库时网关超时报错,观察日志显示查询请求之后会批量创建几十个连接,这是怎么回事? 这个问题原因前面2中已经说过了,就是因为项目启动时,排除了Druid的自动配置导致连接池没有初始化,而且也没有手动调用初始化方法,解决办法就是定义DataSource的时候进行手动初始化。 问题3:正常查询的过程中,连接被关闭了,为什么? 在线程DestroyConnectionThread的代码中,有一段这样的逻辑: if (isRemoveAbandoned()) { removeAbandoned(); } public int removeAbandoned() { int removeCount = 0; long currrentNanos = System.nanoTime(); List abandonedList = new ArrayList(); activeConnectionLock.lock(); try { Iterator iter = activeConnections.keySet().iterator(); for (; iter.hasNext();) { DruidPooledConnection pooledConnection = iter.next(); if (pooledConnection.isRunning()) { continue; } long timeMillis = (currrentNanos - pooledConnection.getConnectedTimeNano()) / (1000 * 1000); // removeAbandonedTimeoutMillis默认300s,被借出时间超过则close该连接(先放入abandonedList中) if (timeMillis >= removeAbandonedTimeoutMillis) { iter.remove(); pooledConnection.setTraceEnable(false); abandonedList.add(pooledConnection); } } } finally { activeConnectionLock.unlock(); } //close长期不归还的连接 if (abandonedList.size() > 0) { for (DruidPooledConnection pooledConnection : abandonedList) { final ReentrantLock lock = pooledConnection.lock; lock.lock(); try { if (pooledConnection.isDisable()) { continue; } } finally { lock.unlock(); } JdbcUtils.close(pooledConnection); pooledConnection.abandond(); removeAbandonedCount++; removeCount++; if (isLogAbandoned()) { StringBuilder buf = new StringBuilder(); buf.append("abandon connection, owner thread: "); buf.append(pooledConnection.getOwnerThread().getName()); buf.append(", connected at : "); buf.append(pooledConnection.getConnectedTimeMillis()); buf.append(", open stackTrace\n"); StackTraceElement[] trace = pooledConnection.getConnectStackTrace(); for (int i = 0; i buf.append("\tat "); buf.append(trace[i].toString()); buf.append("\n"); } LOG.error(buf.toString()); } } } return removeCount; }默认情况下removeAbandoned=false,可是如果设置了removeAbandoned=true并且指定了removeAbandonedTimeoutMillis(默认5分钟)的话,就会对被借出去的连接进行检测:如果连接从被get出去到当前的时间间隔超过removeAbandonedTimeoutMillis的话,就会将此连接close,这个机制主要是为了防止应用从池子中拿到连接后由于某种故障或者没有close而导致长时间没有归还到连接池,从而导致连接泄露。此功能默认关闭,一般也不需要开启。所以如果一定要设置这个参数的话,建议removeAbandonedTimeoutMillis要设置大于sql执行的时间,否则就会出现sql还在执行却被close的情况。 上面介绍的是连接池初始化流程和获取连接流程的工作原理,这里附上两张完整的Druid工作流程图供大家参考: Druid工作原理-连接池初始化流程: 2、可能有同学注意到了DruidDataSource类中也有一个close()方法,那么它跟上面说的连接回收方法DruidPooledConnection.close()有什么区别呢?看下DruidDataSource.close()方法的代码就能很清楚了: public void close() { if (LOG.isInfoEnabled()) { LOG.info("{dataSource-" + this.getID() + "} closing ..."); } lock.lock(); try { if (this.closed) { return; } if (!this.inited) { return; } this.closing = true; if (logStatsThread != null) { logStatsThread.interrupt(); } if (createConnectionThread != null) { createConnectionThread.interrupt(); } if (destroyConnectionThread != null) { destroyConnectionThread.interrupt(); } if (createSchedulerFuture != null) { createSchedulerFuture.cancel(true); } if (destroySchedulerFuture != null) { destroySchedulerFuture.cancel(true); } for (int i = 0; i connHolder.getStatementPool().closeRemovedStatement(stmtHolder); } connHolder.getStatementPool().getMap().clear(); Connection physicalConnection = connHolder.getConnection(); try { physicalConnection.close(); } catch (Exception ex) { LOG.warn("close connection error", ex); } connections[i] = null; destroyCountUpdater.incrementAndGet(this); } poolingCount = 0; unregisterMbean(); enable = false; notEmpty.signalAll(); notEmptySignalCount++; this.closed = true; this.closeTimeMillis = System.currentTimeMillis(); disableException = new DataSourceDisableException(); for (Filter filter : filters) { filter.destroy(); } } finally { lock.unlock(); } if (LOG.isInfoEnabled()) { LOG.info("{dataSource-" + this.getID() + "} closed"); } }DruidDataSource.close()方法是对连接池进行关闭回收,当然它也会关闭物理连接和所有Statement(这很好理解,连接池都回收了,池中的连接以及相关Statement肯定也要关闭)。所以这来两个类的close()方法作用是不同的: DruidDataSource.close()DruidDataSource.close()方法是回收连接池的,主要用于系统关闭时或者Spring容器销毁时调用,可以通过@Bean注解指定: |
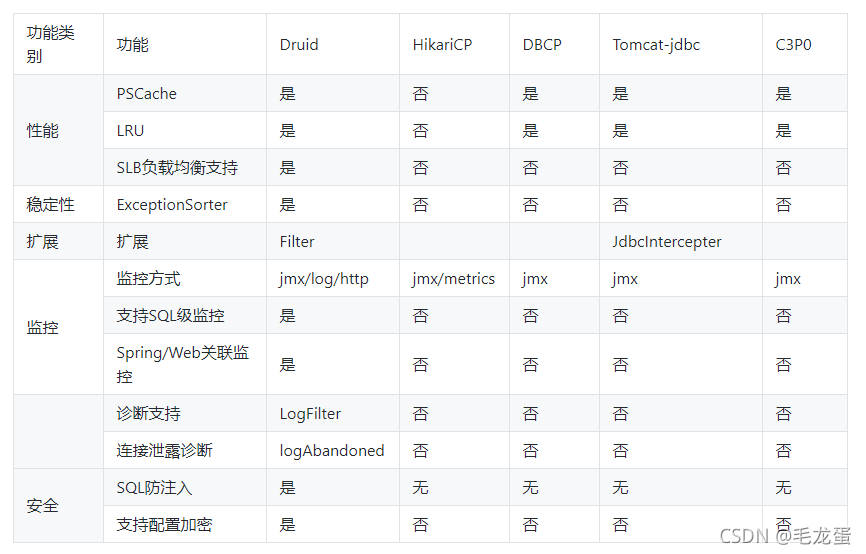 从上表可以看出,Druid连接池号称是业界最优秀的连接池,在性能、监控、诊断、安全、扩展性这些方面远远超出竞品。
从上表可以看出,Druid连接池号称是业界最优秀的连接池,在性能、监控、诊断、安全、扩展性这些方面远远超出竞品。 当然,我们自己也可以扩展,Druid支持通过SPI的方式加载; 以上信息都是摘自官网,更多详细介绍参见官网:https://github.com/alibaba/druid/wiki/Druid%E8%BF%9E%E6%8E%A5%E6%B1%A0%E4%BB%8B%E7%BB%8D
当然,我们自己也可以扩展,Druid支持通过SPI的方式加载; 以上信息都是摘自官网,更多详细介绍参见官网:https://github.com/alibaba/druid/wiki/Druid%E8%BF%9E%E6%8E%A5%E6%B1%A0%E4%BB%8B%E7%BB%8D 在spring.factories文件中:
在spring.factories文件中: 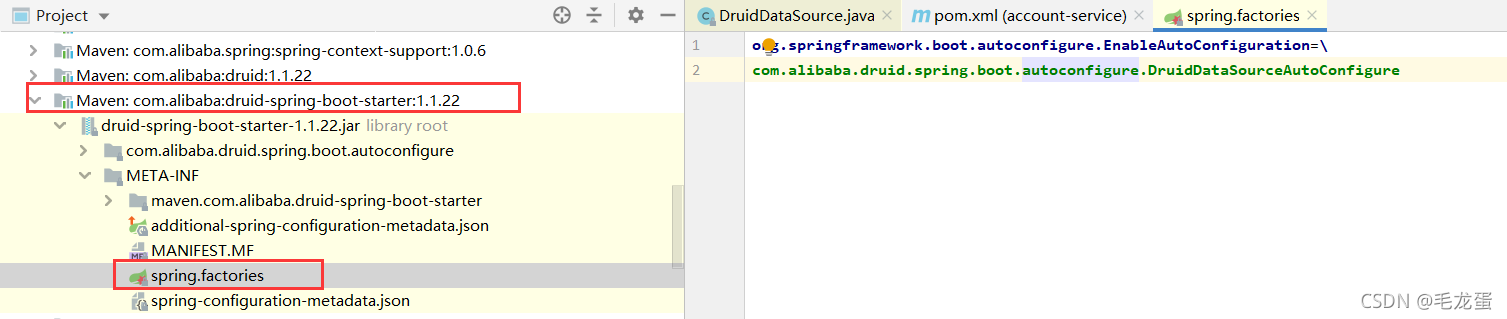 该文件中配置了Druid的自动配置类:com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure,
该文件中配置了Druid的自动配置类:com.alibaba.druid.spring.boot.autoconfigure.DruidDataSourceAutoConfigure, 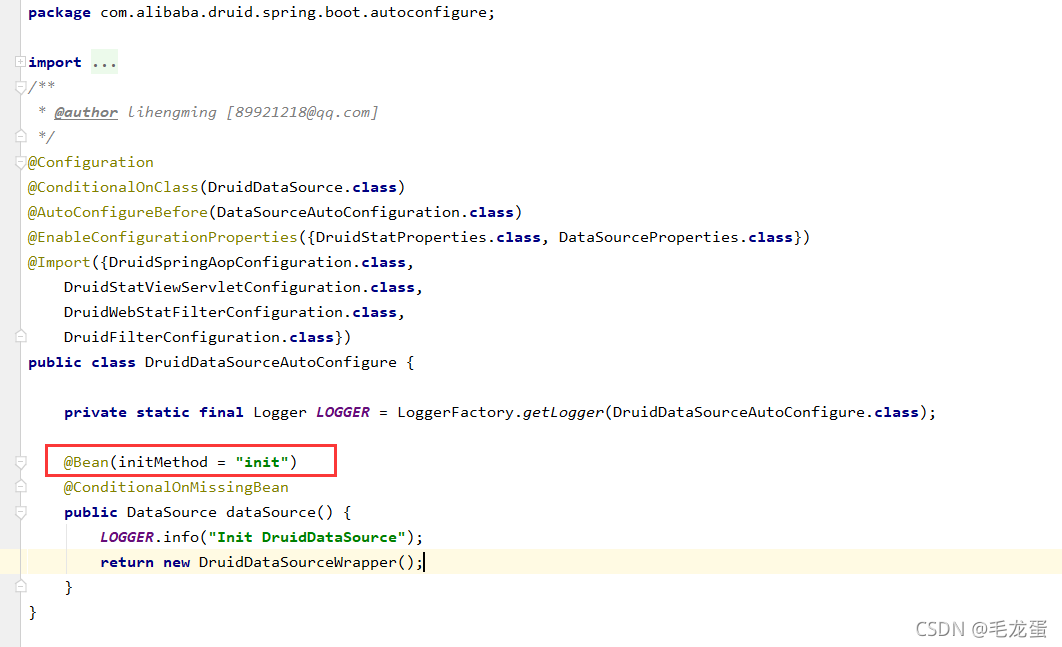 如上图,初始化DataSource这个bean的时候就会执行init()方法,这也就是为什么项目启动后会自动进行Druid的初始化,当然,如果项目不是Springboot,可以在定义DataSource的时候手动调用init()方法。 返回的是DruidDataSourceWrapper类,继承了DruidDataSource类,是DataSource的包装类,主要作用是容错:正常Druid默认都是读取spring.datasource.druid.xxx(DruidDataSource、DruidAbstractDataSource类中的属性都是读取的这个前缀下的配置)下的配置,但是如果没有配置spring.datasource.druid前缀,则就读取spring.datasource的配置,主要是用户名、密码、url、数据库驱动类这几个必填配置,其它配置参数即使不配也没关系,有默认值。
如上图,初始化DataSource这个bean的时候就会执行init()方法,这也就是为什么项目启动后会自动进行Druid的初始化,当然,如果项目不是Springboot,可以在定义DataSource的时候手动调用init()方法。 返回的是DruidDataSourceWrapper类,继承了DruidDataSource类,是DataSource的包装类,主要作用是容错:正常Druid默认都是读取spring.datasource.druid.xxx(DruidDataSource、DruidAbstractDataSource类中的属性都是读取的这个前缀下的配置)下的配置,但是如果没有配置spring.datasource.druid前缀,则就读取spring.datasource的配置,主要是用户名、密码、url、数据库驱动类这几个必填配置,其它配置参数即使不配也没关系,有默认值。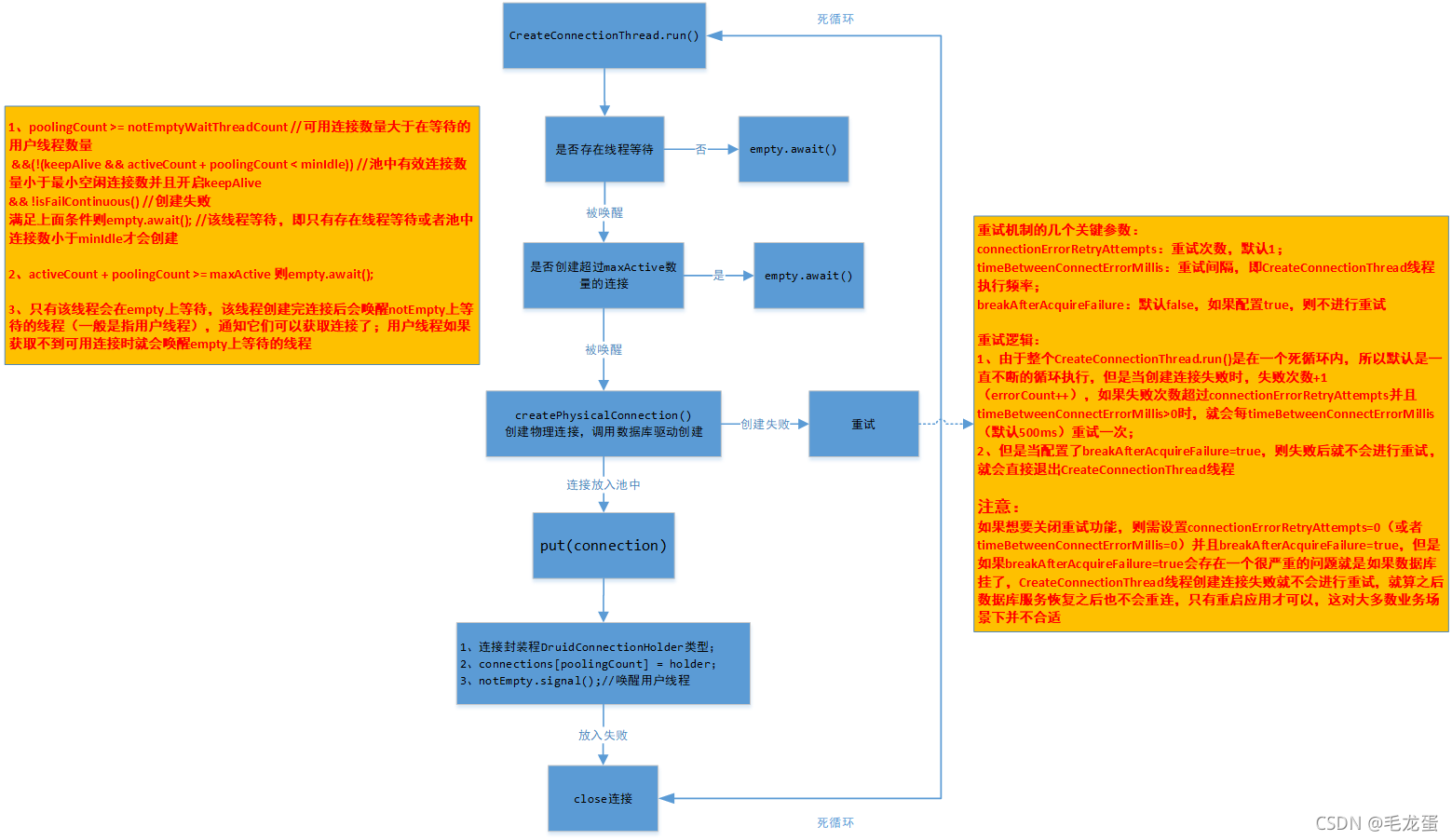 虽然该线程在初始化时就开启了,并且线程内部就是一个死循环,但是大多数情况下这个线程是不工作的,处于WAITING状态,所以不用担心线程在空轮询消耗cpu。它的等待通过empty.await()实现,empty是Condition类型(条件锁,这是jdk并发包中用于线程间协作的工具),与之相对的另一个Condition类型的变量notEmpty,它们俩保证了用户线程和CreateConnectionThread线程的良好协作:初始化完成后CreateConnectionThread线程在empty上阻塞住,当连接池中连接不够时(比如用户线程拿走一个连接时或者关闭掉不可用连接后)就会唤醒该线程,同时notEmpty.await()阻塞用户线程;如果连接池满了,那么就会唤醒用户线程来拿连接:notEmpty.signal,同时阻塞CreateConnectionThread线程,所以这就是一个生产者-消费者模式。
虽然该线程在初始化时就开启了,并且线程内部就是一个死循环,但是大多数情况下这个线程是不工作的,处于WAITING状态,所以不用担心线程在空轮询消耗cpu。它的等待通过empty.await()实现,empty是Condition类型(条件锁,这是jdk并发包中用于线程间协作的工具),与之相对的另一个Condition类型的变量notEmpty,它们俩保证了用户线程和CreateConnectionThread线程的良好协作:初始化完成后CreateConnectionThread线程在empty上阻塞住,当连接池中连接不够时(比如用户线程拿走一个连接时或者关闭掉不可用连接后)就会唤醒该线程,同时notEmpty.await()阻塞用户线程;如果连接池满了,那么就会唤醒用户线程来拿连接:notEmpty.signal,同时阻塞CreateConnectionThread线程,所以这就是一个生产者-消费者模式。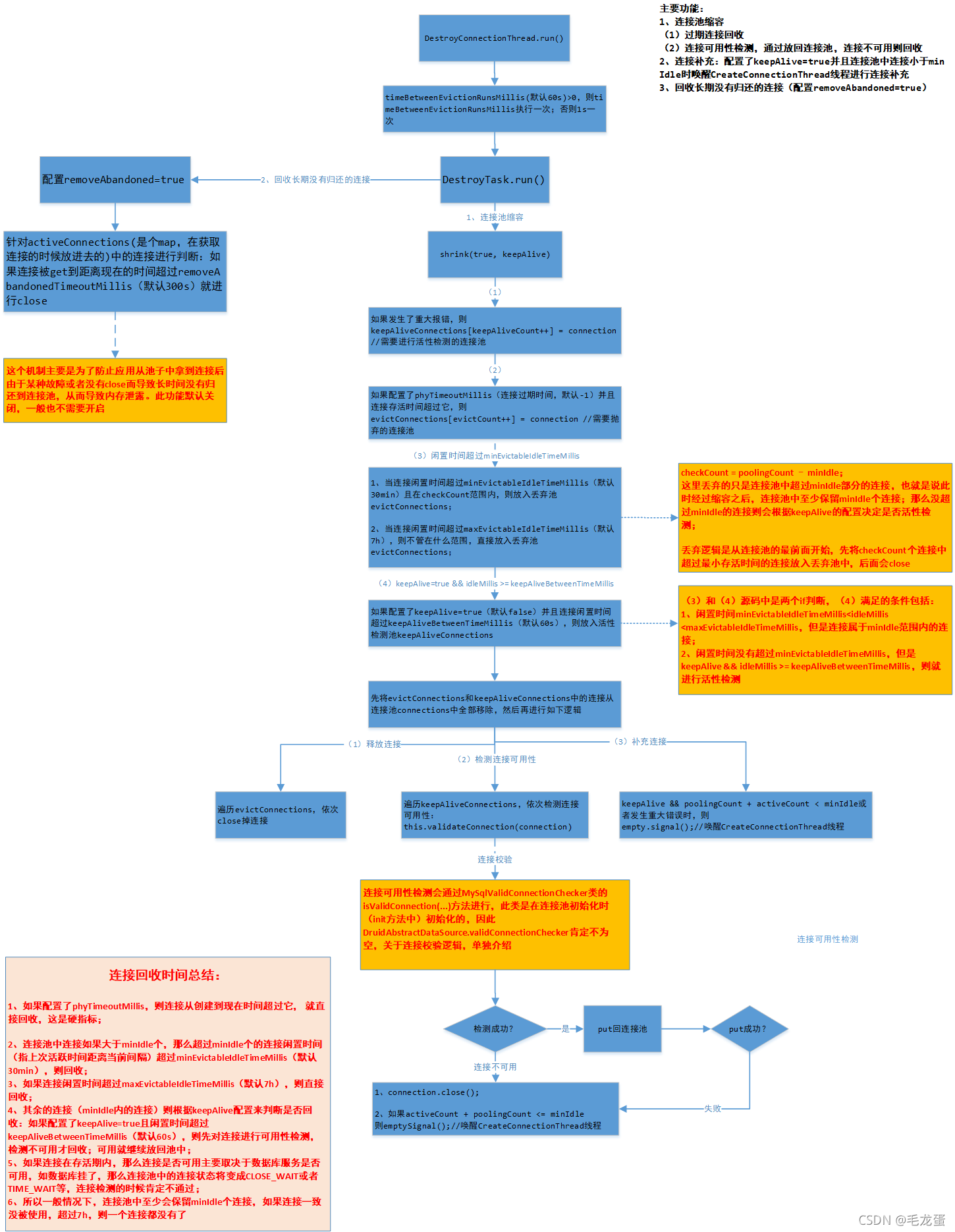
 总结: 1、只有mysql有ping方式检测连接可用性,而且默认情况下mysql是采用ping方式(其它数据库都是采用validateQuery); 2、如果要想通过配置的validateQuery来进行检测怎么办呢?根据MySqlValidConnectionChecker类的构造方法可以知道,需要配置jvm参数:-Ddruid.mysql.usePingMethod=false; 3、所以如果是mysql数据库,仅仅配置validateQuery是不行的,还要添加Ddruid.mysql.usePingMethod=false配置; 4、如果池中原本有超过minIdle个连接,那么经过回收之后,池中至少会保持minIdle个连接在里面;
总结: 1、只有mysql有ping方式检测连接可用性,而且默认情况下mysql是采用ping方式(其它数据库都是采用validateQuery); 2、如果要想通过配置的validateQuery来进行检测怎么办呢?根据MySqlValidConnectionChecker类的构造方法可以知道,需要配置jvm参数:-Ddruid.mysql.usePingMethod=false; 3、所以如果是mysql数据库,仅仅配置validateQuery是不行的,还要添加Ddruid.mysql.usePingMethod=false配置; 4、如果池中原本有超过minIdle个连接,那么经过回收之后,池中至少会保持minIdle个连接在里面;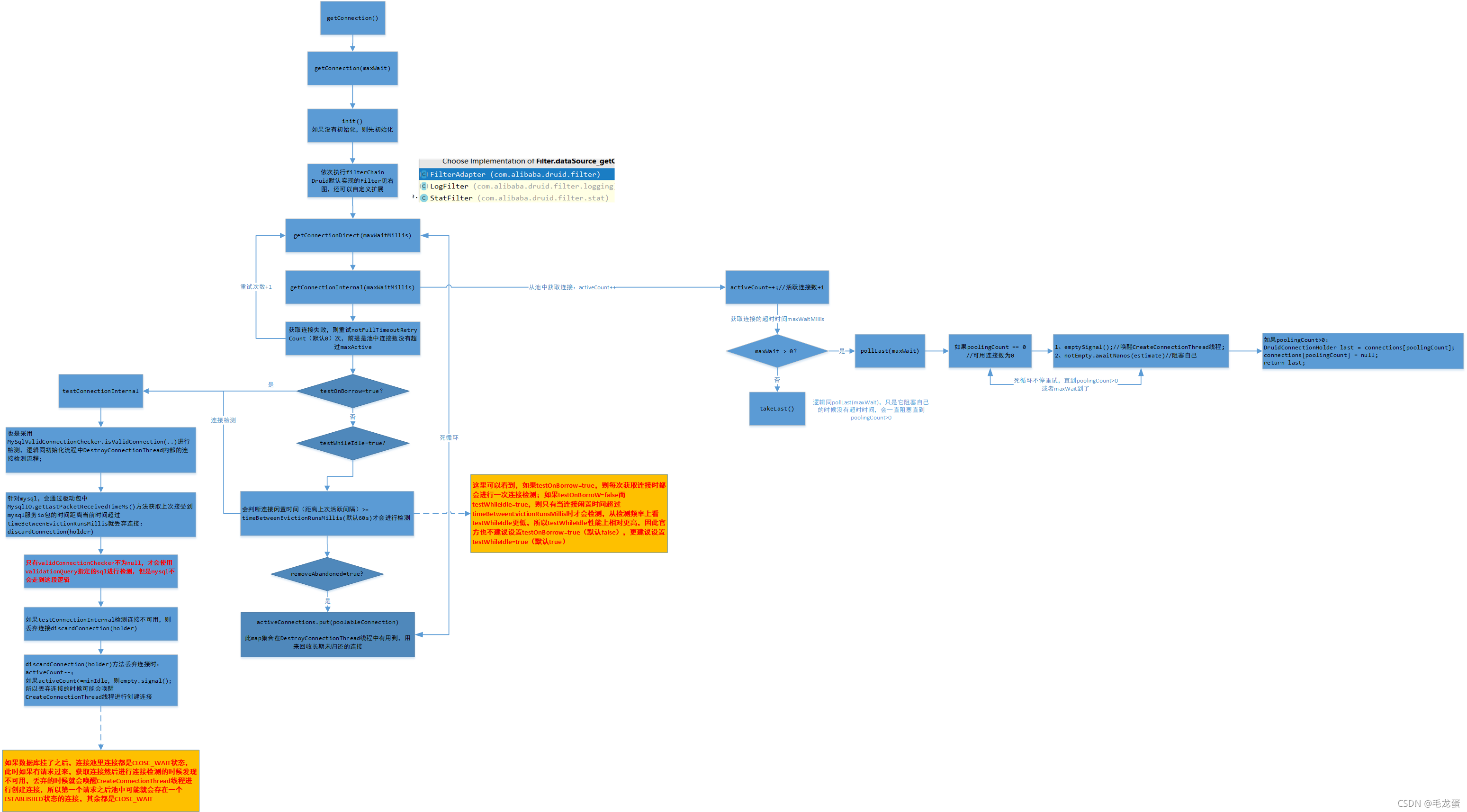 (1)获取连接的时候也会先去检查一下连接池是否已经初始化,如果没初始化就先初始化,一开始说了项目启动后会自动初始化,那么对于下图配置来说,此时连接池是已经初始化了还是没初始化?答案是没有初始化……因为此项目启动时给排除了这个类的自动加载:
(1)获取连接的时候也会先去检查一下连接池是否已经初始化,如果没初始化就先初始化,一开始说了项目启动后会自动初始化,那么对于下图配置来说,此时连接池是已经初始化了还是没初始化?答案是没有初始化……因为此项目启动时给排除了这个类的自动加载: 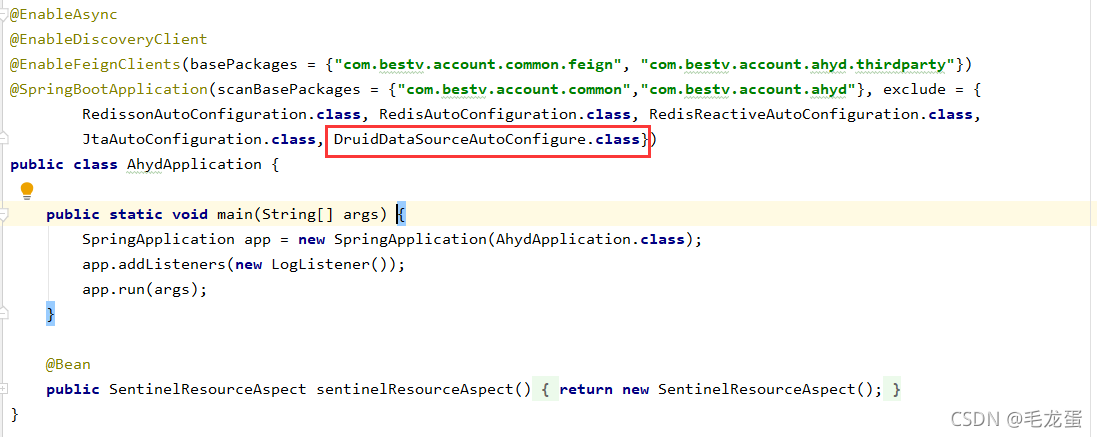 所以没有加载Druid的自动配置类DruidDataSourceAutoConfigure,也就不会进行自动初始化了,那么就会在获取连接的时候再初始化。这个逻辑本身没什么问题,但是我们最好手动提前给初始化,尽量不要将初始化后置到获取连接的时候,比如项目实际配置的initialSize=50,如果是在获取连接的时候(即实际查询的时候)再初始化,就会在查询之前先创建50个连接,还有一些其它一系列的操作(见前面初始化流程),这就可能耗费很长时间影响查询性能,甚至可能造成超时报错,所以需要在定义DataSource的时候手动调用一下初始化方法:
所以没有加载Druid的自动配置类DruidDataSourceAutoConfigure,也就不会进行自动初始化了,那么就会在获取连接的时候再初始化。这个逻辑本身没什么问题,但是我们最好手动提前给初始化,尽量不要将初始化后置到获取连接的时候,比如项目实际配置的initialSize=50,如果是在获取连接的时候(即实际查询的时候)再初始化,就会在查询之前先创建50个连接,还有一些其它一系列的操作(见前面初始化流程),这就可能耗费很长时间影响查询性能,甚至可能造成超时报错,所以需要在定义DataSource的时候手动调用一下初始化方法: 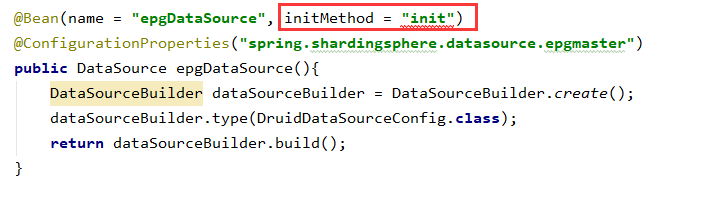 疑问: 那么为什么我们要排除DruidDataSourceAutoConfigure类的自动加载呢?是因为我们项目使用了shardingsphere,它与shardingsphere的数据源配置冲突了,为啥会冲突呢? 原因在前面1.1其实已经说过了:Druid默认都是读取spring.datasource.druid.xxx(DruidDataSource、DruidAbstractDataSource类中的属性都是读取的这个前缀下的配置)下的配置,但是如果没有配置spring.datasource.druid前缀,则就读取spring.datasource的配置,主要是用户名、密码、url、数据库驱动类这几个必填配置,但是使用了shardingsphere后,配置前缀变成了spring.shardingsphere.datasource.xxx,这时Druid显然读取不到用户名、密码、url、数据库驱动类这些必填配置了,就会报错,所以才要排除Druid的自动配置。不过不用担心排除了Druid的自动配置导致spring容器中没有DataSource数据源了,shardingsphere的自动配置类里也会加载数据源:见org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration
疑问: 那么为什么我们要排除DruidDataSourceAutoConfigure类的自动加载呢?是因为我们项目使用了shardingsphere,它与shardingsphere的数据源配置冲突了,为啥会冲突呢? 原因在前面1.1其实已经说过了:Druid默认都是读取spring.datasource.druid.xxx(DruidDataSource、DruidAbstractDataSource类中的属性都是读取的这个前缀下的配置)下的配置,但是如果没有配置spring.datasource.druid前缀,则就读取spring.datasource的配置,主要是用户名、密码、url、数据库驱动类这几个必填配置,但是使用了shardingsphere后,配置前缀变成了spring.shardingsphere.datasource.xxx,这时Druid显然读取不到用户名、密码、url、数据库驱动类这些必填配置了,就会报错,所以才要排除Druid的自动配置。不过不用担心排除了Druid的自动配置导致spring容器中没有DataSource数据源了,shardingsphere的自动配置类里也会加载数据源:见org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration (3)然后就是从池中获取连接,如果获取不到的话,就唤醒CreateConnectionThread线程(empty.signal())创建连接,上面流程图已经很详细展示了整个流程,就不再细说了。
(3)然后就是从池中获取连接,如果获取不到的话,就唤醒CreateConnectionThread线程(empty.signal())创建连接,上面流程图已经很详细展示了整个流程,就不再细说了。 Druid工作原理-获取连接流程:
Druid工作原理-获取连接流程:  3、连接回收
3、连接回收 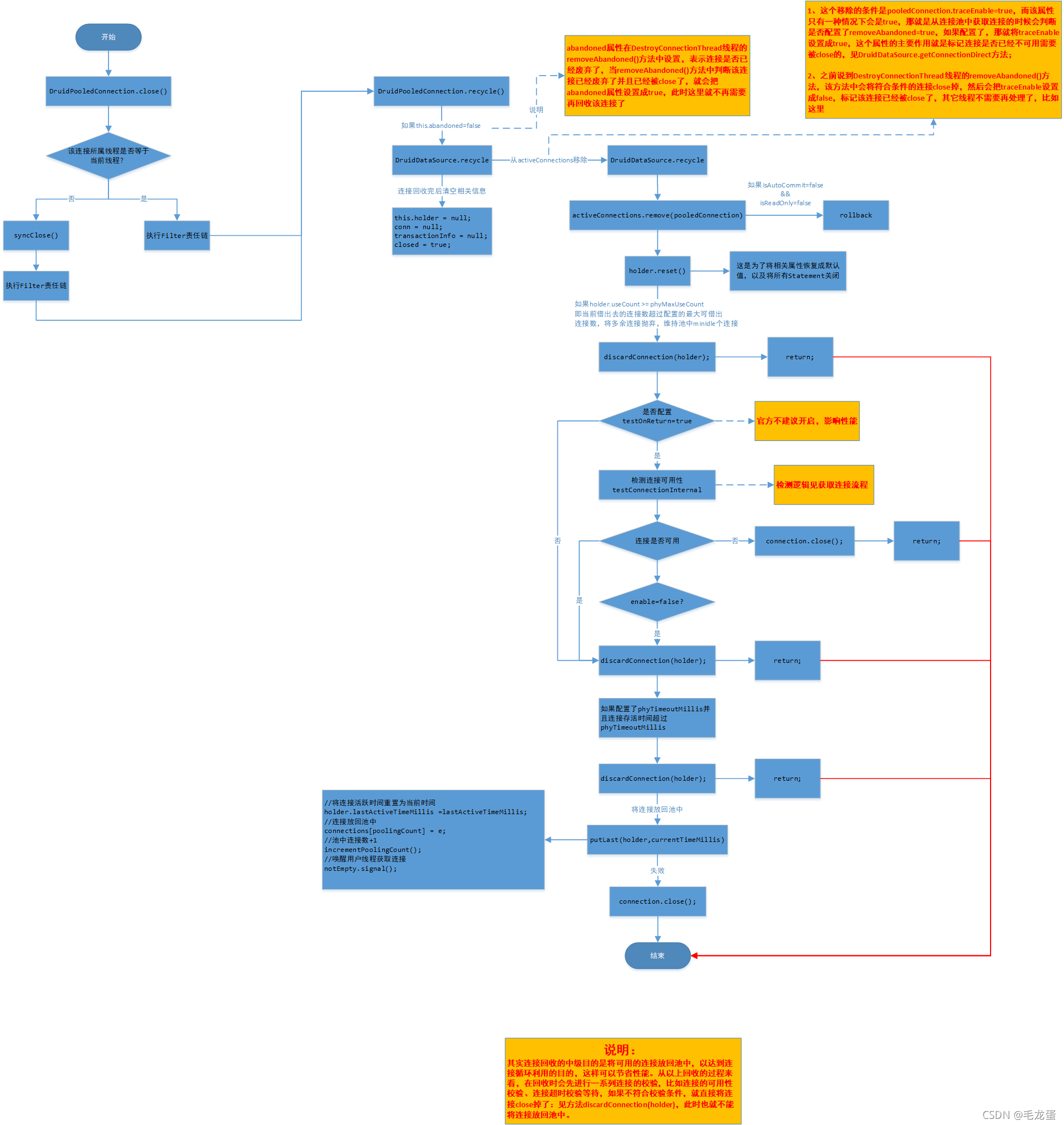 说明: 1、其实连接回收的中级目的是将可用的连接放回池中,以达到连接循环利用的目的,这样可以节省性能。从以上回收的过程来看,在回收时会先进行一系列连接的校验,比如连接的可用性校验、连接超时校验等待,如果不符合校验条件,就直接将连接close掉了:见方法discardConnection(holder),此时也就不能将连接放回池中。
说明: 1、其实连接回收的中级目的是将可用的连接放回池中,以达到连接循环利用的目的,这样可以节省性能。从以上回收的过程来看,在回收时会先进行一系列连接的校验,比如连接的可用性校验、连接超时校验等待,如果不符合校验条件,就直接将连接close掉了:见方法discardConnection(holder),此时也就不能将连接放回池中。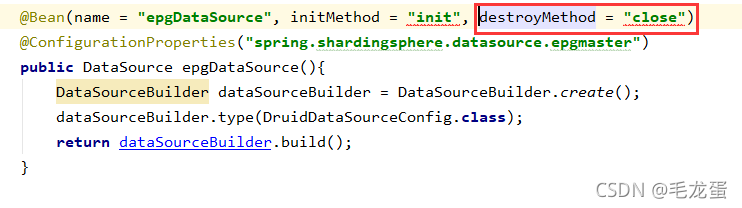 一般我们根本用不到这个功能,也不需要进行连接池的手动回收,当发生以上场景时基本上应用系统进程停了或者故障挂了,那么连接池也会随着进程被回收了;
一般我们根本用不到这个功能,也不需要进行连接池的手动回收,当发生以上场景时基本上应用系统进程停了或者故障挂了,那么连接池也会随着进程被回收了;【本文地址】